FITS images
Resampling of image pixels
In the analysis of astronomical FITS images, one frequently needs to resample an image to a new image with different pixel positions. This may include a translation and rotation of the image and a change in the pixel size.
A common tool for these operations is the Montage package that implements the Drizzle algorithm (Fruchter & Hook, 2002, PASP 112, 144 ). The algorithm maps the pixels of the source image onto the target image. The value of each pixel in the target image is calculated as an average of the input pixels, weighted according to the overlap (the area) between the source pixels and the target pixel. One can also include a drizzling factor to shrink the size of the input pixels before the calculation of the overlap.
We tested how the algorithm would perform when parallelised with OpenCL and especially if GPUs would allow some speedup. We wrote a proof-of-concept programme that consists of a Python routine (about 30 lines of code) and the OpenCL kernel (less than 200 lines of code). The program is short because the coordinate transformations are handled by calls to the astropy library. The main logic is:
- The python routine converts pixel coordinates of the input image to sky coordinates and further to pixel coordinates in the target image. This makes use of the header information of both images.
- The kernel is provided the mapping between pixel coordinates, it calculates the overlapping areas, and returns the resampled output image
The image below shows the time it takes to resample an N×N pixel image to another N×N image. In the reprojection the input an output FITS images have a relative offset of a couple of pixels and a relative rotation of 30 degrees. The OpenCL routine is run either on CPU or on GPU. We use for comparison the Montage package routine reproject that is run using a single CPU thread. In these tests (images in tangential projection), Montage actually spends most of the time in the routine mProjectPP. For the OpenCL routine, in the case of the GPU run, the figure also shows separately the time spent in the host Python code (the coordinate transformations), the building of the kernel code, and the actual kernel execution.
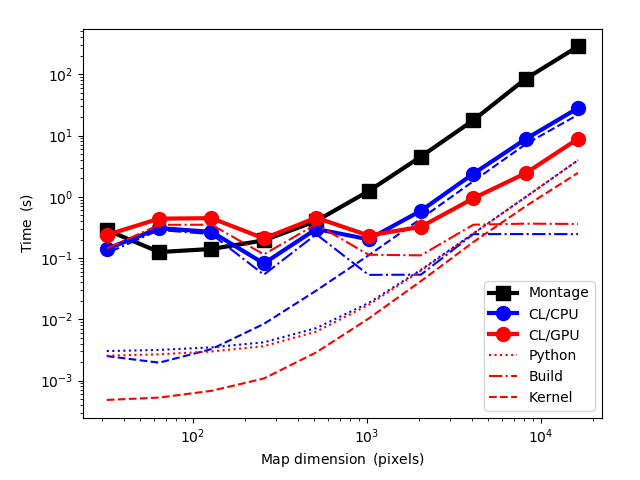
One can make some observations:
- For maps up to the size pf 512×512 pixels, the OpenCL run times are dominated by the kernel build times (shown as dotted lines) and the run times are similar to those of Montage.
- In the case of larger maps, the build time of the OpenCL kernels become unimportant and most of the time is spent in the kernel execution and in the Python host code. In GPU runs, the run time is actually dominated by the latter.
- For large maps the scaling is similar for all programs. Relative to the single-thread Montage run, the OpenCL program is on CPU faster by a factor of 10.1 and on GPU faster by a factor of 33.
The runs were made on a laptop with six CPU cores (with hyperthreading) so the factor of ten between the Montage runs on a single core and the parallel OpenCL CPU runs is more or less expected, close to perfect scaling. The GPU is still more than a factor of three faster.
There are some caveats to this comparison. In the figure the dotted lines correspond to the time spent in the Python routine, which consists mainly of the coordinate transformations. There is probably little Python-overhead from the use of the aplpy routines but these are executed in a single thread, without parallelisation. We actually computed coordinates only at steps of five input pixels and the kernel used linear interpolation to get the coordinates for the intervening pixels. If Python were used (sequentially) to computed coordinate transformations for every input pixel, that cost would determine the overall speedup relative to Montage.
Below is a comparison of the Montage and OpenCL-program results for one synthetic 256×256 image that covers a sky area of 4.2×4.2 degrees near zero latitude. The programs give mostly similar results with relative differences well below 10⁻⁴, as shown in the last frame of the figure. However, the differences are large at the borders which are handled differently by the programs.

The main conclusion is that GPUs look promising (also) for the image resampling. Further speedup relative to the proof-of-concept code should also be possible, for example via the parallelisation of the coordinate transformations.
The above tests were run on a laptop with a six core i7-8700K CPU running at 3.70 GHz and with an Nvidia GTX-1080 GPU. The program can be found at GitHub , in the FITS subdirectory.
We ran the above test also on another laptop that has only four cores. The computer has an integrated Intel graphics processor and also an external GPU enclosure with an NVidia GTX 1080 Ti GPU. The next figure shows the run times for Montage (on a single single thread), laptop CPU (four cores), the internal GPU, and the external GPU.

The speedup relative to a single-thread Montage run is 4.3 with the CPU, 14.0 with the internal GPU, and 47.6 with the external GPU. In this case the coordinate transformation were calculated explicitly only at intervals of ten input pixels, which ensured that the run time is dominated by the kernel code. However, even in the case of the external GPU, the time spent in the host Python program was several times smaller than the time required by the kernel execution. In other words, one could afford to compute coordinate transformations on a somewhat denser grid without a significant effect on the total run time.

The figure above shows histograms of the relative difference between the Montage reproject and the OpenCL routine (after masking the edges of the covered areas!). The input maps are 256×256 pixels in size, with pixel values in the range [1.0, 100.0] units. The maps were generated by first having a constant level +2.0 units, adding Gaussian fluctuations N(0,1), and further adding 1000 compact sources at random locations, with a peak values of 100.0 units and with Gaussian intensity profiles (FWHM ~ two pixels). The projections include both translation and rotation. The plot shows results four pixel sizes (columns of frames) and four values of the step (in units of the input image pixel size) at which the coordinate transformations are explicitly calculated (rows of frames and the parameter cstep). Each frame quotes the maximum absolute difference max(Δ) and the maximum relative difference, max(r) = (Montage-OpenCL)/Montage. It seems that coordinates calculated explicitly at intervals ~8 arcmin provide results that are accurate to ~0.1% (peak errors). In other words, accurate results are possible without sacrificing the speed-up indicated in the previous figure. However, the errors will depend on the projection. This test used tangential projections for both the input and output images and further testing is needed.
These tests were run on a laptop with a four core i7-8550U CPU running at 1.80GHz (and more prone to throttling in long calculations). The internal GPU was Intel Corporation UHD Graphics 620 and the GPU in the external exclosure NVidia GTX 1080 Ti. The histogram plot was made with the script test_drizzle_errors.py in GitHub directory FITS.
Convolution
Convolution is another basic operation needed in astronomical image analysis. Fast fourier transform (FFT) is the most efficient method when the convolving beam is large. However, with parallel processing and GPU computing, it is still feasible to do the convolution in real space, even when the beam is relatively large. The figure below compares the run times of direct FFT, the convolution implementations in Scipy and astropy, and the OpenCL real-space convolution run with CPU and two GPUs (for hardware details, see the previous section). The images are 1260×1260 pixels in size and the FWHM of the convolving beam is given on the x axis. The astropy routine allows missing values and the weighting of individual pixels in the beam averaging. This is true also for the OpenCL routine but the GPU allowing a speedup of up to two orders of magnitude relative to the astropy routine. For FFT the run time is independent of the beam size and it is still the fastest for very large convolution kernels (although without accounting for missing values or individual weighting of the measurements).

The next figure shows one comparison of the astropy and the OpenCL routines. The upper frames show the convolved maps and the lower frames the absolute and the relative differences. Here the border pixels are handled in a similar way by both programs, using the nearest map pixel when part of the convolution kernel falls outside the map. The results are practically identical.

The tests were run on a laptop with a four core i7-8550U CPU, Intel Corporation UHD Graphics 620 integrated GPU (GPU1), and NVidia GTX 1080 Ti (GPU2). The programs can be found in GitHub , in the FITS subdirectory.